Sampling Distribution and Central Limit Theorem
Now that you’ve learned how to determine probabilities and cut-offs for normal distributions, you might wonder how you can be (reasonably) sure that a distribution is normal. After all, the tools we have been using are valid only for normal distributions.
There are various sophisticated techniques for making this determination, one of them is called “Normal Quartile Plot”, which is included in GeoGebra for you to explore.
But more importantly, there’s a way in which every distribution can be turned into a normal one, allowing us to find probabilities and cut-offs, and this way is part of what we call the Central Limit Theorem, a result from advanced calculus (don’t worry, though), which we will use throughout the inferential statistics part of this course.
What I want to do here is to give you a sense of it, and give you an important formula from it, and let it sit on the back burner until we begin to use it.
Sampling Distribution of Sample Means
One cannot discuss the Central Limit Theorem without the
concept of a sampling distribution, which explains why inferential statistics is not just a blind guess.
Think about women’s heights. We take a woman’s height; maybe she’s shorter than
average, maybe she’s average, maybe she’s taller. We have assumed that these
heights, taken as a population, are normally distributed with a certain mean (65
inches) and a certain standard deviation (3 inches). We called the random
variable for height X. Instead of saying inches, we could write more precisely by
attaching the name of the random variable as a subscript, and
inches,
inches. As we will see in a minute, using
subscripts helps us clarify which distribution we are talking about at the
moment.
Now imagine that we form groups of ten women, many, many such samples, the members of which are randomly selected (say, using random sampling) from the population of women as a whole, and for each sample we look at the sample mean and make a data set of those means rather than the individual heights. This set of sample means is called a sampling distribution, or to be more exact, sampling distribution of sample means. I know this sounds redundant, but it is necessary to use all fo these words to fully convey what we are doing. A picture may help you see it better:

I’ve included some sample means just to emphasize that they
are not all equal to the original population mean ![]() inches. Although only
3 samples are shown, the sampling distribution actually contains infinitely
many means, since the original population is infinite.
inches. Although only
3 samples are shown, the sampling distribution actually contains infinitely
many means, since the original population is infinite.
Here is what you need to create a sampling distribution:
1. Pick a sample size and a statistic (say the mean)
2. Randomly draw a sample from the population with the same size
3. Calculate the statistic from the sample and record it
4. Repeat from Step #2
Central Limit Theorem for Sample Means
Now we might want to find the usual things about the set of
means a measure of central tendency and a measure of
variation.
You can think of this measure of central tendency as the mean
of the sample means, a kind of a second-level mean (a “second-level
supervisor” if you found the analogy helpful). How do we name this mean
mathematically? Using our naming convention, we shall call this ![]() , which reads exactly as “mean of sample mean”.
, which reads exactly as “mean of sample mean”.
Now we are talking about three kinds of means: there is the
original population mean ![]() , which is a fixed number; the sample mean
, which is a fixed number; the sample mean ![]() , which varies with each sample, and this new “mean of sample
means”, what we call
, which varies with each sample, and this new “mean of sample
means”, what we call ![]() . The first and third mean are both parameters, while the
second one is a statistic.
. The first and third mean are both parameters, while the
second one is a statistic.
It shouldn’t come as a surprise that ![]() and
and ![]() should be the same.
You’re taking the same population, taking samples from it, and looking at their
means
should be the same.
You’re taking the same population, taking samples from it, and looking at their
means how could this set of means have a different
mean than the population it came from, which we now call the parent
population? It couldn’t. And it doesn’t matter how big the samples are
which you’re taking to make the sampling distribution. The mean of
![]() ’s will be the same as the mean of the X’s no matter
how many are in the samples (i.e. how big n is). Symbolically,
’s will be the same as the mean of the X’s no matter
how many are in the samples (i.e. how big n is). Symbolically, ![]() . This is the first piece of the Central Limit Theorem.
. This is the first piece of the Central Limit Theorem.
But the standard deviation, the measure of variation, is a
different story. It might not be that unusual to find a woman who is at least
six feet tall. According to our parameters, ![]() , or approximately 1% of women fall in this category. But how
unusual it would be to find a randomly-selected sample of ten women whose average
height is at least six feet. If some of them were under six feet, there
would have to be some very tall ones to average six feet or more as a group.
And the likelihood of all ten being at least six feet tall is nearly none,
unless you are watching a basketball team.
, or approximately 1% of women fall in this category. But how
unusual it would be to find a randomly-selected sample of ten women whose average
height is at least six feet. If some of them were under six feet, there
would have to be some very tall ones to average six feet or more as a group.
And the likelihood of all ten being at least six feet tall is nearly none,
unless you are watching a basketball team.
Can you also see that the larger the sample size n that
is used for the sampling distribution, the more unlikely it is that samples
will have means very different from the mean of the parent population? So it’s
not true that ![]() . In fact, the formula looks like this:
. In fact, the formula looks like this:
![]()
The bigger n is, the larger number you’re dividing into the standard deviation of the parent population, and the smaller the quotient. When you have n approaches infinity, then you are almost drawing the entire population at once, and the sample mean will always land at the population mean, leading to a standard deviation of zero.
But if the standard deviation of women’s height is 3 inches, the standard deviation of the sample mean of 10 women is:
![]()
In other words, ![]() And the probability that the average height of 10 women is
over six feet is:
And the probability that the average height of 10 women is
over six feet is:
![]()
The probability is so small that GeoGebra simply displays zero, since we are talking about 5 standard deviation away from the mean here.
Some books give the standard deviation of the sampling
distribution, ![]() , a special name. It’s called the standard error of the
mean, because of its use in statistics. But when you first start, you
should probably just stick with standard
deviation of the sample mean.
, a special name. It’s called the standard error of the
mean, because of its use in statistics. But when you first start, you
should probably just stick with standard
deviation of the sample mean.
So a sampling distribution, while not changing the mean of the parent distribution, tightens it up and draws it together, and the larger the sample size the greater this effect. But that’s not all it does. Remember how I said that every distribution could in some sense become a normal one? That’s the last piece of what the Central Limit Theorem does for us.
First of all, if the parent distribution is itself a normal one, then the sampling distribution is also normal, no matter what the sample size, n, is. However, for any parent distribution, even the most un-normal ones, as n gets bigger, the sampling distribution looks more and more normal, and at a certain point you might as well just consider it normal for the purposes of finding probabilities and cut-offs. And what is that point? It turns out that if n is at least 30, in other words if the sampling distribution is made up of samples of size 30 or more, then the distribution may be considered approximately normal.
Demonstration of Central Limit Theorem
Since sampling distribution and Central Limit Theorem are probably two of the most abstract topics in the text, it helps to be able to visualize them with the help of some technology.
Open the applet from the following link: http://onlinestatbook.com/stat_sim/sampling_dist/. After reading the instructions, click "Begin" on the left to launch the applet.

- What
happens when you click “Animated”?
(A random sample is drawn from the parent population, and the sample mean is computed)
- How
are the 2nd and 3rd figures related to the first
figure in the applet?
(2nd figure is the sample, 3rd figure is the sampling distribution of sample means) - Click
the buttons named “5 samples”, and “10,000 samples”. What happened each time?
(More and more sample means are generated by repeating the random sampling process)
- Keep drawing more samples until the statistics of sample means stop changing. Record the mean and standard deviation of Sample Means (shown in the 3rd table on the right side) below in the appropriate row.
|
Sample size |
Mean of sample means |
Std dev of sample means |
|
n=1 (population) |
|
|
|
n=5 |
|
|
|
n=16 |
|
|
|
n=25 |
|
|
(Note: the standard deviation of sample means should decrease as n increases)
- Reset
the applet by click "Clear lower 3". Repeat Steps 1 4 until you have completed the table with your experimental results. What is the effect of changing the sample size when you examine these statistics?
(as the sample size increases, the mean of sample means approaches the original population mean, while the standard deviation decreases according to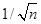 )
)
The web applet also allows you to change the parent distribution from normal to something else (e.g. uniform), and you can still see the Central Limit Theorem at work.
So here are the three pieces of the Central Limit Theorem for sample means:
1.
The mean of the sample means is the same as
population mean, i.e. ![]()
2.
The standard deviation of the sample means
decreases as the sample size increases, i.e. ![]()
3.
The distribution of the sample means approaches
a normal distribution, under certain conditions, i.e. ![]()
Assumptions for the Application of CLT
The first part of the Central Limit Theorem regarding the
normality of the sample means is not an obvious fact. Specifically, either one
of these two conditions must be met before we can treat the sampling
distributions of sample means (![]() ) as a normal distribution). The first condition states that:
) as a normal distribution). The first condition states that:
· The original (parent) distribution (X) itself is normal.
But this may be too much to ask, since as we saw in the class data: many of the quantitative variables do not even look symmetrical (such as AGE0, let alone normal. What makes Central Limit Theorem special is the second condition:
· The sample mean is taken over a somewhat large sample size (typically n > 30 is used).
As seen in the simulation in the last section, when the distribution of X is not normal to begin with (say uniform or skewed), the sampling distribution of means does not look normal for small n. But as n increases, the familiar bell-shaped curve start to emerge. Although this is another place where we wish we had calculus to be able to back up our claims, computer-based simulations provide an excellent window into how abstract mathematical truths such as CLT are able to predict the outcomes of random experiments.
Problem Solving with the CLT
Have you noticed the sign posted inside the elevator? It usually says the capacity in terms of pounds, and the maximum number of passengers. Here is a picture from a Japanese elevator:

Although you probably don’t read Japanese, you can probably guess that 1150 kg (2535 lbs) is the weight limit, and the elevator can fit at most 12 people. Suppose the population of people who use this elevator has normally distributed weights with a mean of 180 lb and a standard deviation of 40 lb. If this elevator is used by the same population of men, how often does the elevator exceed capacity when it’s full (n=12)?
Suppose 12 men enter the elevator and their total weight is exactly 2535 lbs. Then their average weight is 211 lbs. If we look at the probability of one person exceeding 211 lbs, it is:
![]()
About 1 in 5 times, which will be quite frustrating if you
have to take it every day. But this is not what we are looking for. Since in a
group of 12, the heavier people are going to be balanced by the light-weight
people, we should be looking at the probability that the average weight exceeds
211 lbs, i.e.![]() .
.
Since CLT tells us that ![]() , we arrive at something much more reasonable:
, we arrive at something much more reasonable:
![]()
Sampling Distribution and CLT of Sample Proportions
(This section is not included in the book, but I suggest that you read it in order to better understand the following chapter. You can skip it for now, and revisit after you have done the reading for Chapter 8. )
Sampling distribution and Central Limit Theorem not only apply to the means, but to other statistics as well. Since we are about to start inferential statistics in Chapter 8, let's revisit a picture that we saw a few weeks ago, when we first started the chapter on probability:

Instead of having marbles and pail, let's replace them with something more interesting -- Reese's pieces, which I'm sure most people have had a taste of. For those of you who haven't had Reese's pieces lately, let me remind you that there are three colors in Reese's pieces, orange, yellow, and brown (the colors that made the brand's logo).

Imagine we have a huge inventory of Reese's pieces. We start
by having each group draw 10 Reese's pieces, which represents a random sample
with sample size ![]() . Based on their respective sample, if someone needs to give
an estimate of the real proportion of orange pieces among all Reese's pices,
the best guess one can give is simply based on counting the number of orange
pieces, then divided by the size of the sample. In Chapter 8, we call this a
"point estimate" for the population proportion (which is unknown):
. Based on their respective sample, if someone needs to give
an estimate of the real proportion of orange pieces among all Reese's pices,
the best guess one can give is simply based on counting the number of orange
pieces, then divided by the size of the sample. In Chapter 8, we call this a
"point estimate" for the population proportion (which is unknown):
![]()
If you want some visual demonstration, this applet can be quite helpful: http://www.rossmanchance.com/applets/OneProp/OneProp.htm?candy=1

For example, if you counted 6 orange pieces in a batch of
10, then ![]() . Because of the randomness in choosing the samples, the
. Because of the randomness in choosing the samples, the ![]() value will vary
depending on the sample. If we look at
value will vary
depending on the sample. If we look at ![]() as a random variable,
and consider all the possible values of
as a random variable,
and consider all the possible values of ![]() , these values (ranging from
, these values (ranging from ![]() ) form a "sampling
distribution of sample proportions". This may look like a lot of words
for a single symbol, but I haven't found a way to use fewer words to convey the
same idea. Perhaps the following picture, similar to the one we used for sample
means, will help you understand sampling distribution a little further:
) form a "sampling
distribution of sample proportions". This may look like a lot of words
for a single symbol, but I haven't found a way to use fewer words to convey the
same idea. Perhaps the following picture, similar to the one we used for sample
means, will help you understand sampling distribution a little further:

The blue bubbles on the left represent individual samples
(they might overlap since it was taken with replacement). Each sample produces
a statistic ![]() . So the sampling distribution is a distribution of
"statistic-s", which is another way to think about this concept.
. So the sampling distribution is a distribution of
"statistic-s", which is another way to think about this concept.
Because in our example, there are so few pieces in the
sample (a total of 10), it is actually possible to calculate the probability of
each ![]() using the binomial
probability from Chapter 5, if we know the population proportion
using the binomial
probability from Chapter 5, if we know the population proportion ![]() . Recall that binomial probability requires we known the
total sample size
. Recall that binomial probability requires we known the
total sample size ![]() and the probability of
success
and the probability of
success ![]() (in this case, the
proportion of orange pieces). Assuming that we are taking 10 pieces at a time,
and there are exactly 50% orange pieces (
(in this case, the
proportion of orange pieces). Assuming that we are taking 10 pieces at a time,
and there are exactly 50% orange pieces (![]() ), by using the binomial calculator in GeoGebra, we can
calculate the probability distribution as follows:
), by using the binomial calculator in GeoGebra, we can
calculate the probability distribution as follows:
![]() Probability
Probability
0 P(x=0) = 0.001
0.1 P(x=1) = 0.01
0.2 P(x=2) = 0.04
......
0.9 P(x=9) = 0.01
1.0 P(x=10) = 0.001
You can verify these probabilities by using the binomial
calculator. The calculation for ![]() (which corresponds to
(which corresponds to ![]() ) is shown in the following screen shot:
) is shown in the following screen shot:

Notice the shape of the binomial distribution is very similar to that of the normal distribution, except that binomial is discrete, and normal is continuous. In fact, there is a version of the Central Limit Theorem (not included in the book) that addresses exactly this issue:
· Central Limit Theorem for Sample Proportions:
1.
The
sampling distribution for the sample proportion ![]() is approximately
normal
is approximately
normal
2.
The mean of ![]() is equal to
is equal to ![]() , i.e.
, i.e. ![]()
3.
The standard deviation of ![]() is equal to
is equal to ![]() , i.e.
, i.e. ![]()
To see why this is true, recall that in a previous lecture,
we showed that ![]() follows a binomial
distribution with mean
follows a binomial
distribution with mean ![]() , and standard deviation
, and standard deviation ![]() . Since
. Since ![]() , divide the mean and standard deviation each by
, divide the mean and standard deviation each by ![]() , we have the mean of
, we have the mean of ![]() :
:
![]() ,
,
and the standard deviation of ![]() :
:
![]()
One useful example for thinking about the standard deviation
of ![]() (which we will
represent using
(which we will
represent using ![]() ) is by varying the sample size
) is by varying the sample size ![]() : if you take a small hand of orange pieces (say 4), then
compared to
: if you take a small hand of orange pieces (say 4), then
compared to ![]() pieces, it's much more
likely you will get some extreme values for
pieces, it's much more
likely you will get some extreme values for ![]() , such as all orange (
, such as all orange (![]() ), or no orange (
), or no orange (![]() ). Although the mean
). Although the mean ![]() stays the same (50%
orange), the standard deviation is larger for
stays the same (50%
orange), the standard deviation is larger for ![]() , since there are fewer pieces in the sample. As we learned
in algebra, the value of
, since there are fewer pieces in the sample. As we learned
in algebra, the value of ![]() decreases as
decreases as ![]() increases.
increases.
Central Limit Theorem and the Small-Sample Illusion
The Central Limit Theorem has some fairly profound implications that may contradict our everyday intuition. For example, if I tell you that if you look at the rate of kidney cancer in different counties across the U.S., many of them are located in rural areas (which is true based on the public health data). What is going through your mind?
(Think about this question before you read the next paragraph.)
Within the space between these two paragraphs, you probably thought of a dozen possible explanations, many of them making perfect sense: rural areas have fresher air, rural people exercise more, healthier diets, well water without chlorine, etc. Some of you may be thinking that perhaps this is another example of correlation, but not causation. But what if I give you another piece of information: if you look at the counties with the highest rates of kidney cancer, a large proportion of them are also rural counties. In other words, when you look at the data, not only is there no causation, there isn't any correlation either. In fact, many of the counties with the lowest (in green) and highest (in orange) rates of kidney cancer are adjacent to each other. But they have one thing in common: location in a rural area, which translates to small populations.

Assuming that nothing really strange is going on in Rural America, what could be going on here?
It turns out that the rate of kidney cancer is just a
massive example of the Reese's pieces. Instead of counting the proportion of
orange pieces, we are counting the proportion of kidney cancer. What distinguishes
rural counties from their urban counterparts is their size: rural counties have
fewer people living in them compared to the cities. So the rural county is like
the example of ![]() , while the urban county is like
, while the urban county is like ![]() . As we saw above, the standard deviation is much larger for
the smaller sample, therefore explaining the extreme values that you obtain
from the rural counties.
. As we saw above, the standard deviation is much larger for
the smaller sample, therefore explaining the extreme values that you obtain
from the rural counties.
Failure to understand the Central Limit Theorem can lead to some costly mistakes. One is example of the "small school" movement that was backed by several foundations (notably, Gates Foundation and Annenberg Foundation). The idea originated in the observation that among the nation's best performing schools, many of them are small schools with few students. Several million dollars then went into breaking larger public schools into smaller, "specialized" schools that hopefully boost the success rate of students. Unfortunately, these efforts did not produce the expected results. It turns out that the difference between small and large schools is yet another example of the effect of changing the sample size. In the following graph, the change in the average 4th grade math assessment score is plotted again the size of the school. A positive change thus indicates an improvement; while a negative change indicates perhaps a school is performing “poorly”:

If you look at the schools with the worst performance (a
negative change in 4-th grade Math scores), you will find many of them are
small schools of 60 or fewer students. In fact, there are about as many
“failing” schools as the “successful” schools. What we have learned from CLT told
us that perhaps “failing” and “successful” are just both illusory labels that
we put on the data they are the reflection of the fact that
sample means from small samples tend to have more variation.
The small-sample illusion illustrates one of the innate limitations of human cognition: we are not naturally inclined to think statistically about the information we receive. This is one of the good reasons why it’s good for everyone to take this course!