Binomial Distribution
After studying the random variables and discrete probability
distributions, we need to look a little more closely at a special type of
discrete distribution, one that is closely related to the example we used
earlier about the number of boys when you have 4 kids. What characterize these
types of distributions is that they can all be seen as repeated coin flips ![]() you can call the two outcomes boys/girls,
heads/tails, or whatever. But the mathematics is really the same.
you can call the two outcomes boys/girls,
heads/tails, or whatever. But the mathematics is really the same.
Binomial Random Distribution based on a Fair Coin
Suppose we have a fair coin (so the heads-on probability is 0.5), and we flip it 3 times. If we let the random variable X represent the number of heads in the 3 tosses, then clearly, X is a discrete random variable, and can take values ranging from 0 to 3. Moreover, we can represent the probability distribution of X in the following table:
|
x |
P(x) |
|
0 |
|
|
1 |
|
|
2 |
|
|
3 |
|
What will be the probability of ![]() ? We can do it in one of two ways: since the coin is
fair, the sample space has 8 equally likely outcomes {HHH, HHT, HTH, HTT, THH,
THT, TTH, TTT}. So the chance of 0 heads is just the probability of getting all
tails, i.e.
? We can do it in one of two ways: since the coin is
fair, the sample space has 8 equally likely outcomes {HHH, HHT, HTH, HTT, THH,
THT, TTH, TTT}. So the chance of 0 heads is just the probability of getting all
tails, i.e. ![]() . Alternatively, we can also use independence of the 3
coin tosses, and break down the probability using the multiplication rule,
applied to the independent events:
. Alternatively, we can also use independence of the 3
coin tosses, and break down the probability using the multiplication rule,
applied to the independent events: ![]() . Using the
same reasoning, it's also easy to determine that
. Using the
same reasoning, it's also easy to determine that ![]() . So our probability distribution now becomes:
. So our probability distribution now becomes:
|
x |
P(x) |
|
0 |
1/8 |
|
1 |
|
|
2 |
|
|
3 |
1/8 |
The probability ![]() is slightly
more complicated. Using the classical probability approach, the event that
"there is 1 head in 3 tosses" includes 3 separate outcomes: {HTT,
THT, TTH}. So the probability of getting 1 head is
is slightly
more complicated. Using the classical probability approach, the event that
"there is 1 head in 3 tosses" includes 3 separate outcomes: {HTT,
THT, TTH}. So the probability of getting 1 head is ![]() .
.
But there is another way that uses the additional rule and multiplication rule together that you should know: since "1 head" is technically a union of the three outcomes: HTT, THT, TTH, and they are mutually exclusive; we may use the addition rule applied to the mutually exclusive events:
![]()
![]()
![]()
You probably noticed that the three probabilities being added are all the same, so we can shorten it as:
![]()
So the factor of 3 comes from the use of the addition rule,
and the ![]() is a result of
applying the multiplication rule. Using the same type of analysis, we can also
determine that
is a result of
applying the multiplication rule. Using the same type of analysis, we can also
determine that ![]() . Hence the completed probability distribution is the
following:
. Hence the completed probability distribution is the
following:
|
x |
P(x) |
|
0 |
1/8 |
|
1 |
3/8 |
|
2 |
3/8 |
|
3 |
1/8 |
This Binomial distribution also allows us to answer other questions related to the experiment, and it’s useful to look at some of the common phrases used to describe these events:
·
The probability of the coin landing heads more
than once is denoted by ![]() .
.
·
The probability of the coin landing heads fewer
than three times is denoted ![]() .
.
·
The probability of the coin landing heads at
least twice is denoted by ![]() . The "at least" phrasing means we're
looking for the probability of the coin landing heads two or more times.
. The "at least" phrasing means we're
looking for the probability of the coin landing heads two or more times.
·
The probability of the coin landing heads at
most twice is denoted by ![]() . The "at most" phrasing means we're looking
for the probability of the coin landing tails two times or fewer.
. The "at most" phrasing means we're looking
for the probability of the coin landing tails two times or fewer.
·
The probability of the coin landing heads
between one and three times, inclusive, is denoted by ![]() .
.
Assumptions of Binomial Distribution
What you just saw was a binomial distribution, which is the generalized version of a fixed number of coin flips. Here are the assumptions of the binomial distribution that were listed in the lecture:
- There
are a fixed number of trials. (represented by the variable
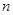 )
)
- Each trial has 2 outcomes (called "success" and "failure" for convenience)
- The trials are all independent of one another.
- The
probability of success is the same for all trials. (this probability is represented by
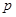 , and
, and 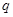 represents
the probability of failure -- the opposite of success)
represents
the probability of failure -- the opposite of success)
For the experiment above, the number of trails ![]() , and the probability of success
, and the probability of success ![]() . Using these two parameters, we can determine the
entire probability distribution.
Although the calculations using the addition and multiplication rules
may seem complicated, it's quite important to understand them, since as we see
next, it's the only way to evaluate the binomial probabilities when the
heads-on probability
. Using these two parameters, we can determine the
entire probability distribution.
Although the calculations using the addition and multiplication rules
may seem complicated, it's quite important to understand them, since as we see
next, it's the only way to evaluate the binomial probabilities when the
heads-on probability ![]() is no longer
equal to 0.5.
is no longer
equal to 0.5.
Binomial Distribution based on an Unfair Coin
To see the flexibility of the binomial distribution, let's imagine that someone glued some chewing gum on one side of the coin (on a side note, one of my previous Math 15 students did this as part of his term project. So we know this can be done). As a result, the coin is no longer fair. The same can be said about the chance of having boys: in reality, it’s never 50%. Around the world, the birth rate for boys is slightly higher than the girls. How do we calculate the binomial probabilities if the heads-on probability is not 50%?
Suppose the chewing gum makes heads occur more (60% of the time) often than tails (40% of the time). So how would this affect the probability distribution of a "bent" coin if it's still tossed 3 times?
Since the coin is no longer the same, we will give this
random variable a different name -- ![]() . The distribution of
. The distribution of ![]() includes the
same range of values as
includes the
same range of values as ![]() , since the number of trials
, since the number of trials ![]() did not change.
The only thing that changes was that
did not change.
The only thing that changes was that ![]() changed from
0.5 to 0.6, and
changed from
0.5 to 0.6, and ![]() changed from
0.5 to 0.4 (but we really just need to know one of them)
changed from
0.5 to 0.4 (but we really just need to know one of them)
|
y |
P(y) |
|
0 |
|
|
1 |
|
|
2 |
|
|
3 |
|
But instead of ![]() , which is what you expect from a fair coin. We can
expect that
, which is what you expect from a fair coin. We can
expect that ![]() will be less
than 1/8, since the chewing gum has made the tail less likely to turn up at
each toss. Here we can no longer using the classical probability approach of
"number of ways that event occurs / size of sample space", since the
outcomes are clearly not equally likely. For example, HHH is now much more
likely than TTT.
will be less
than 1/8, since the chewing gum has made the tail less likely to turn up at
each toss. Here we can no longer using the classical probability approach of
"number of ways that event occurs / size of sample space", since the
outcomes are clearly not equally likely. For example, HHH is now much more
likely than TTT.
So instead of counting the event and dividing everything by
8, we will have to use the multiplication rule, since the 3 tosses are still
independent of each other. So to find ![]() , we break it town as follows:
, we break it town as follows:
![]()
![]()
This is quite a bit less than 1/8=0.125, as expected, but we can also write the probability in a slightly different format that leads to a general formula:
![]()
It might be strange to include ![]() here, since
it's just another way to write 1 in there. But if you think about it a little
differently,
here, since
it's just another way to write 1 in there. But if you think about it a little
differently, ![]() also means
there are zero heads, so the power for the head/tail probability corresponds to
the number of heads/tails in the
also means
there are zero heads, so the power for the head/tail probability corresponds to
the number of heads/tails in the ![]() tosses.
tosses.
Let's move on to look at ![]() . Using the same analysis we did above for
. Using the same analysis we did above for ![]() , we can use the addition rule and multiplication rule
together as follows:
, we can use the addition rule and multiplication rule
together as follows:
![]()
![]()
![]()
![]()
Although there are 3 different orders that 1 head, 2 tails can occur in 3 tosses, each outcome has the same probability, which is reflected in the factor of 3. Using the same strategy, we can look at the probability of 2 heads:
![]()
And 3 heads:
![]()
To make sure, we can verify that this is indeed a
probability distribution by adding up the probabilities: ![]() .
.
|
y |
P(y) |
|
0 |
0.064 |
|
1 |
0.288 |
|
2 |
0.432 |
|
3 |
0.216 |
General Formula for Binomial Probability
To summarize, to find the probability of any number of heads, we use the following general principle:
![]()
What if we toss the same bent coin more than 3 times? Things
get a little more complicated from here. For example, if we toss the coin 4
times, then to find the probability there are exactly 2 heads, there are
actually 6 different orders: HHTT, HTTH, HTHT, TTHH, THTH, THHT. The kind of
math you need to work out the number of ways ![]() heads come up
in
heads come up
in ![]() tosses is
related to something called “Pascal Triangle”, and the subject of combinatorics,
which is a branch of mathematics. For those of you who are interested, you can
learn more about combinatorics in Math 4 (Discrete Mathematics), taught at
SRJC.
tosses is
related to something called “Pascal Triangle”, and the subject of combinatorics,
which is a branch of mathematics. For those of you who are interested, you can
learn more about combinatorics in Math 4 (Discrete Mathematics), taught at
SRJC.
If you don't want to look under the hood of the binomial formula, a convenient alternative is to use GeoGebra or your graphing calculator (included in the textbook).
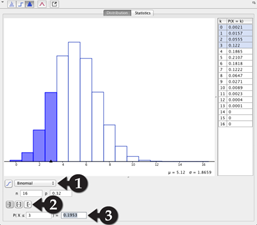
Binomial Calculator in GeoGebra
Open up the probability calculator window by selecting it from the View menu. A dialogue box should appear, though it may appear behind the main window.
1. Ensure that Binomial mode is selected from the pull-down menu.
2. Toggle
between ![]() ,
, ![]() , and
, and ![]() by selecting
the -], [-], and [- buttons,
respectively.
by selecting
the -], [-], and [- buttons,
respectively.
3. From here, one need only insert the relevant information into the relevant fields, and record the calculated value.
Notice that GeoGebra always assume the equal sign is
included in the probability calculations. So if you wish to calculate something
that doesn’t include the equal sign, e.g. ![]() , make sure to rewrite it so that you are evaluating
the same event in GeoGebra (e.g.
, make sure to rewrite it so that you are evaluating
the same event in GeoGebra (e.g. ![]() )
)
Example: Rolling a fair die
Problem: What is the probability of rolling a fair die six times and getting two fours?
First you may wonder: is this a binomial experiment? Although the die has 6 sides, we are only interested in only two kinds of outcomes: four and not four. Let’s check the rest of the assumptions: there is a fixed number of trials (six), trials in the experiment can be defined in terms of success and failure (rolling a four is a success, not rolling a four is considered a failure), and each trial is an independent event (since rolling a number does not affect future die rolls)
In this experiment there are six trials, so ![]() .
.
A success in this experiment is rolling a four, and the
probability of this event is ![]() , so
, so ![]() .
.
A failure in this experiment is not rolling a four, and the
probability of this event is ![]() , so
, so ![]() . Even if this probability was unknown, it could be
found by remembering that $ q $ is the complement of $ p $. It is known that
. Even if this probability was unknown, it could be
found by remembering that $ q $ is the complement of $ p $. It is known that ![]() and that
and that ![]() , so
, so ![]() .
.
The probability of rolling two fours in the experiment is
denoted by ![]() , since this is the probability of rolling exactly two
fours. The information known is thus:
, since this is the probability of rolling exactly two
fours. The information known is thus:
![]()
Using this as input in GeoGebra, it is found that the probability of rolling a fair die six times and getting exactly two fours is approximately 0.2009:
![]()
Mean and Standard Deviation of Binomial Distribution
Earlier in the chapter, we saw that the population mean, or the expected value, of a discrete probability distribution is defined as follows:
![]()
For a binomial distribution, the same equation would apply, and one just has to make sure to add up all the rows in the probability distribution. So for the bent coin we saw above, we will need to add another column to represent what is being added:
|
y |
P(y) |
|
|
0 |
0.064 |
0 |
|
1 |
0.288 |
0.288 |
|
2 |
0.432 |
0.864 |
|
3 |
0.216 |
0.648 |
Adding up numbers in the last column, we found the expected value:
![]()
But it should not surprise you that we could have used a much simpler method: simply multiplying the number of tosses by the heads-on probability: 3*0.6 = 1.8 will give us the same answer. After all, if roughly 60% of the tosses are heads, then the expected value should just be 60% of all tosses.
It turns out that this intuitive reasoning is totally legitimate: if we use the complicated Binomial probability formula introduced above to evaluate each P(x) in the expected value, at the end of the day (omitting a full page of derivation, which you don’t have to know), the expected value of a Binomial distribution is simply:
![]()
It’s rare that the expected value of a discrete distribution turns out to be so simple. But this is really an exception rather than the norm.
By using the same complicated formula, the variance for a binomial probability distribution is also remarkably simple:
![]()
In this formula, n is the number of trials in the experiment and p is the probability of success, and q=1-p is the probability of failure.
Since it’s the square root of variance, the Standard Deviation for a binomial probability distribution is:
![]()
Again, ![]() is the number
of trials in the experiment,
is the number
of trials in the experiment, ![]() is the
probability of success, and
is the
probability of success, and ![]() is the
probability of failure.
is the
probability of failure.
Example: Germination of Seeds
When you buy seed packets, it often says how many percent of the seeds are supposed to germinate. Some seeds are more viable than others, and usually the viability decreases during storage. Imagine you bought a packet of 50 seeds that says that 70% of them are supposed to germinate. If you plant all of the seeds, how many starter plants can you expect to grow?
It turns out this problem has all the characteristics of a binomial experiment: we have a fixed number of trials (50 seeds per packet), the same success rate for each seed (70%), and they are relatively independent (assuming you are providing the ideal soil). So using one of the tools listed above, we can calculate the expected value as:
![]()
and the standard deviation is:
![]()
These parameters help you make a fairly good prediction
about the germination: most likely, your starter plants will be within two
standard deviation of the mean: ![]() , which is between 28.6 and 41.4. So if you want to
leave enough room for 42 plants, then you will definitely not run out of space.
, which is between 28.6 and 41.4. So if you want to
leave enough room for 42 plants, then you will definitely not run out of space.
Binomial Distribution for a Large Number of Trials
The binomial distribution starts to look more and more
symmetrical when you increase the number of trials ![]() . Suppose we flip the aforementioned coin 50 times,
i.e. $n=50$ and $p=0.6$, we can look at the histogram of the binomial
distribution in GeoGebra:
. Suppose we flip the aforementioned coin 50 times,
i.e. $n=50$ and $p=0.6$, we can look at the histogram of the binomial
distribution in GeoGebra:

This histogram resembles the so-called “bell-shaped curve”, which we will study in Chapter 7. This handy connection also forms the basis of doing statistical inference on the underlying parameter p, and allows us to answer questions such as “if we get 64 heads out of 100 tosses, is it likely that the coin is fair?”