Sample mean, Expected Value, and Law of Large Numbers
In Chapter 4, we studied discrete random variables and how to find expected value for the random variables. Since the expected value might strike you as very similar to the sample mean in descriptive statistics, it might be useful to compare the sample mean (which we studied in Chapter 2) and the expected value that we are seeing in Chapter 4, since the two notions represent the perspective of statistics and probability, respectively.
In Chapter 2, we learned about the mean from a frequency distribution. In other words, if we know the frequency, or how many times a data value is repeated, we can use the following formula for sample mean:
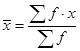
Notice that ![]() is the sample size,
which is the same for all the x. For example, if we rolled a fair, six-sided
die 600 times, then you might see a frequency distribution like the following:
is the sample size,
which is the same for all the x. For example, if we rolled a fair, six-sided
die 600 times, then you might see a frequency distribution like the following:
|
Face |
Frequency |
|
1 |
102 |
|
2 |
108 |
|
3 |
99 |
|
4 |
101 |
|
5 |
94 |
|
6 |
96 |
(Note that I made the frequencies look slightly "random" so that you are not suspecting that I'm making this up:)
If you were going to calculate the mean from this frequency
distribution, then you will do what you did in Chapter 2:
![]()
The mean is equal to 3.44, after rounding. You are probably
not surprised that this is slightly different from 3.5, the expected value for
rolling one die, since each sample of 600 dice rolls may result in a slightly
different statistic -- which is the reason why we used the symbol ![]() to represent the
sample mean.
to represent the
sample mean.
To see how the formula above is connected to the expected value, I'm going to use a little bit of algebra to rewrite the fraction:
![]()
You can see that by rewriting the fraction, I've converted each frequency to a relative frequency, which acts as weights that are multiplied with each face of the die.
This view of the sample mean calculation makes it directly comparable with the expected value formula, i.e.
![]()
Except that instead of using ![]() as weights, we are
using the relative frequency
as weights, we are
using the relative frequency ![]() as weights. They are
actually quite similar in that both need to add up to 1, and the computation is
identical.
as weights. They are
actually quite similar in that both need to add up to 1, and the computation is
identical.
At this point, you might wonder: if expected value is just
another weighted sum using the relative frequency, why do we need another term?
(as if we don't have enough of them already) The answer lies in the distinction
between probability and statistics: in calculating the expected value, we do
not need to spend countless hours rolling the die, if we know it's indeed fair.
Instead of using the relative frequency derived from each sample (e.g. 102/600,
108/600, etc.), we can simply set the probability ![]() , since we know precisely that's how fair dice behave (called
a "uniform distribution" in probability theory). So the expected
value
, since we know precisely that's how fair dice behave (called
a "uniform distribution" in probability theory). So the expected
value ![]() we derive from the
uniform distribution is simply:
we derive from the
uniform distribution is simply:
![]()
Which is a parameter -- a fixed value for a fair die. On the
other hand, ![]() -- the sample mean
calculated from 600 dice rolls, is a statistic that will vary with each sample.
Of course, as you increase the number of dice rolls, you will expect the
relative frequency of each side to approach 1/6, but the relative frequencies
will not be exactly 1/6 until you have infinitely many dice rolls (at this
point, you will have the entire population of dice rolls instead of a sample).
In the mathematical language of limits (which you may have heard of if you have
taken calculus), we say that
-- the sample mean
calculated from 600 dice rolls, is a statistic that will vary with each sample.
Of course, as you increase the number of dice rolls, you will expect the
relative frequency of each side to approach 1/6, but the relative frequencies
will not be exactly 1/6 until you have infinitely many dice rolls (at this
point, you will have the entire population of dice rolls instead of a sample).
In the mathematical language of limits (which you may have heard of if you have
taken calculus), we say that ![]() as
as ![]() . This important fact is also referred to as the "Law of Large Numbers".
. This important fact is also referred to as the "Law of Large Numbers".
So the distinction between the two similar, but different
means basically comes down to what we learned in Chapter 1: ![]() is the statistic,
which varies with each sample;
is the statistic,
which varies with each sample; ![]() is the parameter,
which is fixed when you know the population. Knowing this distinction is
important for understanding what will happen after we study probability: to
make statistical decisions, one must rely on probability and certain
assumptions about the population. Suppose you rolled the dice 600 times and
found the following frequency distribution:
is the parameter,
which is fixed when you know the population. Knowing this distinction is
important for understanding what will happen after we study probability: to
make statistical decisions, one must rely on probability and certain
assumptions about the population. Suppose you rolled the dice 600 times and
found the following frequency distribution:
|
Face |
Frequency |
|
1 |
123 |
|
2 |
110 |
|
3 |
99 |
|
4 |
78 |
|
5 |
85 |
|
6 |
105 |
If I tell you that this is just another fair die, you will probably start to feel suspicious -- rightly so, since the distribution here does not appear to be as "even" as the one above. But how you prove that the die might be loaded? You can point to the sample mean (3.34 in this case), and say it's too far from the expected value of a fair die (3.5). But to say precisely how unlikely this die is indeed fair, we will need to use probability to quantify the chance of getting results like the above from a fair die. If such chance is exceedingly small (say less than one in 1000), then it's a pretty solid proof that the die is indeed loaded.
Based on this miniature example, you can begin to see that black-and-white answers do not exist in statistics. The Law of Large Numbers says that as you get more and more data, the right statistic (such as the sample mean) will give you a more accurate picture of the parameter. The real problem is that we seldom have the luxury of very large data sets. This is where things get interesting, and we will pick this up again in Chapter 6.